
Minería de datos - 202410
Descubriendo el Corazón de Antioquia a través del Análisis de Datos
Universidad del Norte
Barranquilla, Colombiaa. Interacción de Usuarios en el Sitio Web.
En nuestra búsqueda de analizar la interacción de los usuario en el sitio web, intentaremos predecir el número de visitas que dicho usuario tendrá la próxima vez que decida incursionar dentro de la página.
b. Selección del modelo.
Debido al comportamiento de los datos y métricas obtenidas anteriormente, se decidió optar por RandomForest quién fue el que se desempeñó de mejor manera dentro de los métodos de aprendizaje supervisado.
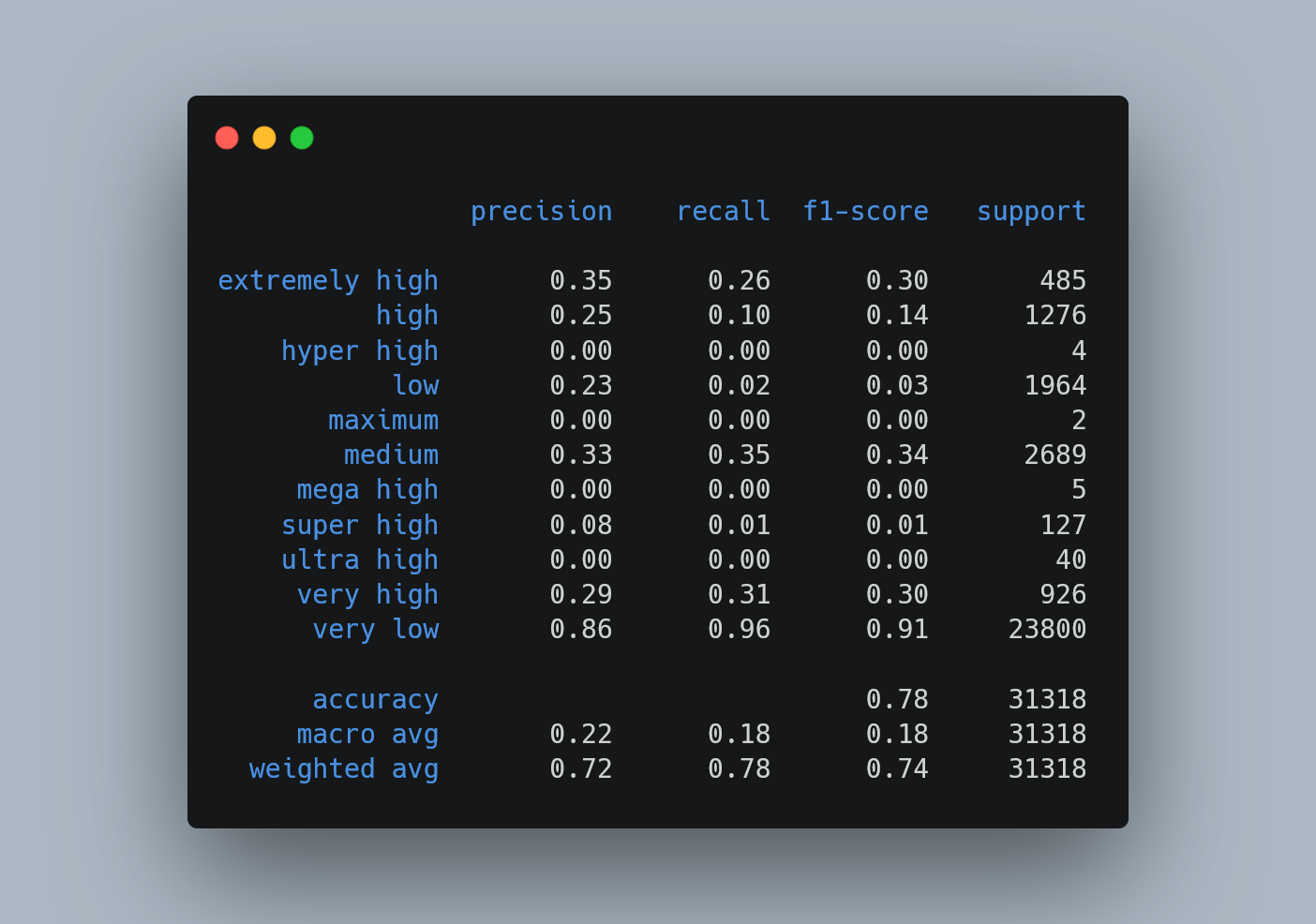
c. Métricas
Dentro de las métricas utilizadas se utilizó el accuracy para identificar el desempeño general del modelo, pero además de ello se hizo un reporte por clases en cual es dónde vemos el rendimiento real del modelo por cada clase. Este último con precision, recall y f1-score.
d. Conclusiones preliminares
Para la elección de los 'features', comenzamos basándonos en el análisis previo de los datos. Existe un sesgo muy grande entre países, siendo Colombia por mucha diferencia la localización de la mayoría navegantes. Por ende, decidimos precindir de cada país y tomar como sitio la ciudad. Además con esto evitamos para esta predicción el uso de latitud y longitud, al no tomarlos en cuenta estaríamos preservando alrededor de 50mil datos más, ya que son alrededor de estos los que no cuentan con estas medidas. Una vez hecho esto analizamos las variables y sus correlaciones de manera que estas no afecten el resultado del modelo al entrenar.
Al final de todo contamos con dos conjuntos de entrada. Las categóricas cómo la ciudad, dispositivo de acceso, URLs visitadas y las númericas cómo promedio de duración en la página, duración de la sesión, año, mes y día.
En la selección de características ('features') para nuestro modelo de predicción, hemos realizado un análisis detallado de los datos previos. Observamos un sesgo significativo entre los países, donde Colombia destaca como la ubicación de la mayoría de los navegantes con una diferencia considerable respecto a otros países. Por lo tanto, decidimos prescindir de la variable país y utilizar en su lugar la variable ciudad como indicador de ubicación. Esta decisión no solo simplifica el modelo al reducir la dimensionalidad, sino que también nos permite evitar el uso de las coordenadas de latitud y longitud. Al no considerar estas últimas, conservamos aproximadamente 50,000 datos adicionales, ya que alrededor de esta cantidad carecen de estas medidas asociadas.
Posteriormente, realizamos un análisis de correlación entre las variables restantes para asegurar que no afecten negativamente los resultados del modelo durante el entrenamiento.
Finalmente, hemos definido dos conjuntos de variables de entrada para nuestro modelo. Por un lado, tenemos las variables categóricas, como la ciudad, el dispositivo de acceso y las URL visitadas. Por otro lado, contamos con variables numéricas, como el promedio de duración en la página, la duración de la sesión, el año, el mes y el día.